数据结构和算法
==算法要学会画图,数形结合!!!!==

C++ STL 常用函数_c++ stl 常用函数-CSDN博客
蓝桥杯算法竞赛系列第0章——蓝桥必考点及标准模板库STL(上)(万字博文,建议抱走)_安然无虞stl-CSDN博客
【两万字精编】蓝桥杯算法竞赛系列第0章——蓝桥必考点及标准模板库STL(下)_stl sprintf-CSDN博客
数组理论基础
数组是存放在连续内存空间上的相同类型数据的集合。数组下标都是从0开始的。
数组可以舍弃下标为0的位置,即直接设计arr[0]=0占位,这样子可以很好和现实世界映射!
字符串处理
二分法(最快了)/我记得老师提过牛顿迭代法,那是个什么
是一种在==有序==数组中查找某一特定元素的搜索算法,这种搜索算法**每一次比较都使搜索范围缩小一半,时间复杂度是log(n)**(高中数学补充过嘞)
- 一是有序数组(这里可能是**==整体有序==**比如[1,2,3,4,5],也有可能是==局部有序==比如[4,5,1,2,3]),
- 二是特定元素(也有可能是满足特定的条件)。由定义我们大概就知道了二分法的应用场景,在有序数组中找特定值都可以考虑用二分法
- 三不能有重复
但是千万不要一直纠结中间的数字两边的数字数量不一样这个问题,因为:
两边数量不一样是一定会出现的情况
但是这种情况并不影响我们对中间数字和目标数字大小关系的判断
只要中间数字大于目标数字,就排除右边的
只要中间数字小于目标数字,就排除左边的
==一个个体在整体面前微不足道==(无非是多排除一个数字或者少排除一个数字)
==真正影响的是中间那个数字到底该不该加入下一次的查找中,也就是边界问题==
二分法的步骤:
我们要确定一个区间[L,R]我们要找到一个性质(由题目条件决定),并且该性质满足一下两点: ①满足二段性 ②答案是二段性的分界点
我们要在一组升序的数组找一个数的下标,那我们肯定是先拿中间的与他进行比较,比较大小的判断,其实就相当于是这个性质,且这个性质满足二段性,将大于和小于我们要查找的值分为两段,而我们的查找结果就是分界点
思路分析:
二分法题目都可以分下面三步:
- 确定是否满足二分法的使用条件 ,有序数组与查找特定元素,题目中a有序,查找的是指定元素test,满足条件
- 确定特定元素test,如:a[pos]=test
- 确定边界的变化,根据定义的第二句话,写出代码如下
妙呀,思想:
第一种写法(左闭右闭)
二分法最重要的两个点:
while循环中 left 和 right 的关系,到底是 left <= right 还是 left < right
迭代过程中 middle 和 right 的关系,到底是 right = middle - 1 还是 right = middle
3.1 正向写法(正确演示)
第一种写法:每次查找的区间在[left, right](左闭右闭区间),根据查找区间的定义(左闭右闭区间),就决定了后续的代码应该怎么写才能对。因为定义 target 在[left, right]区间,所以有如下两点:
循环条件要使用while(left <= right),因为当(left == right)这种情况发生的时候,得到的结果是有意义的
if(nums[middle] > target) , right 要赋值为 middle - 1, 因为当前的 nums[middle] 一定不是 target ,需要把这个 middle 位置上面的数字丢弃,那么接下来需要查找范围就是[left, middle - 1]
第二种写法(左闭右开)
4.1 正向写法(正确演示)
第二种写法:每次查找的区间在 [left, right),(左闭右开区间), 根据区间的定义,条件控制应该如下:
循环条件使用while (left < right)
if (nums[middle] > target), right = middle,因为当前的 nums[middle] 是大于 target 的,不符合条件,不能取到 middle,并且区间的定义是 [left, right),刚好区间上的定义就取不到 right, 所以 right 赋值为 middle。(边界条件无效了)

补充:二分其实还有这种思想(左开右开),就是一来我们将左右范围各移动一位,使实际范围更大,通过移动不断修正范围,直到最后汇聚到中间,l+1=r,二分查找为什么总是写错?_哔哩哔哩_bilibili但是,这也还有问题(这个动态效果,逐渐迫敛)

贪心
通过每次找局部最优从而推导出全局最优,但是其实很多时候不适用,因为全局最优不一定一直是局部最优。
差分
倍增
快速幂算法
快速幂都能做什么?小小的算法也有大大的梦想_哔哩哔哩_bilibili
快速幂算法(全网最详细地带你从零开始一步一步优化)-CSDN博客
就是二进制的一个实现(位于和右移动)O(logn)
这对吗?
- (a + b) % p = (a % p + b % p) % p (1)
- (a - b) % p = (a % p - b % p ) % p (2)
- (a * b) % p = (a % p * b % p) % p (3)
- (abc)%d=(a%db%dc%d)%d;

可以试着自己实现一下快速幂取模(搜到一个这个模重复平方算法)
1 |
|
斐波拉契数列用快速幂找第n项!



龟速乘的根据&实现——慢工出细活
1 | long long quick_mul(long long x,long long y,long long mod) |
实际上,龟速乘的确慢,甚至比直接用开始提到的循环乘法还要慢(因为龟速乘相当于一个自行取模的乘号),然而慢工出细活,正是它的慢最终为我们解决了数据过大时产生的问题。
快速乘
快速幂有关的题:Problem - 2035
回溯算法
BFS算法
哈希/散列(一类算法)
我是看的代码随想录的
哈希究竟代表什么?哈希表和哈希函数的核心原理_哔哩哔哩_bilibili
算法数据结构基础——哈希表(Hash Table)-CSDN博客
数组是通过索引来取出对应的数,哈希是通过==键值对匹配==来取出对应的数!(python字典,c++里面的unordered map,数组,set)
数组通过整数索引找到对应的值(对应其地址),而hash可以通过字符串等多种多样的键去找到值(随机位置,不代表其地址)
- 将任意长度的输入,转换为固定长度的输出

不可逆,所以可以用来单向加密(但是毕竟是有限固定长度,所以会有一个很大的问题:哈希冲突——开放寻址法,封闭寻址法)
- 数据对比
比较哈希函数计算出的哈希值是否一致,来判定文件是否相同
散列表(哈希表) - 散列函数, 冲突处理, 平均查找长度(ASL)_哔哩哔哩_bilibili
哈希一般用于判定一个东西是否在某个集体里出现过
hash一般有三种:数组(范围可控,数据较小),set(数值大),map(有涉及键值对涉及的时候用)
要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。(底层先不管,记住键值对匹配就行)
哈希函数:一种处理方式将内容映射到hash表里

因为有限的hash表肯定会出现有数据多余,出现同一个key(hash碰撞)

一般采取拉链法和线性探测法。
拉链法

其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
#线性探测法(补空位)
一定要保证tableSize大于dataSize
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
哈希表大战表红黑树,数据结构性能挑战赛可以看一下别人做的数据视频,hash速度比红黑树(一种平衡二叉搜索树)快很多
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
那么再来看一下map ,在map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
虽然std::set和std::multiset 的底层实现基于红黑树而非哈希表,它们通过红黑树来索引和存储数据。不过给我们的使用方式,还是哈希法的使用方式,即依靠键(key)来访问值(value)。所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。std::map也是一样的道理。
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
set用于去重,且可以用于数据量大,跨越大的地方(避免空间浪费,不需要自己写hash函数去映射!)
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的。(但是数组不用hash运算,所以速度快,空间换时间)
首先我再强调一下 什么时候使用哈希法,当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value再保存数值所在的下标。
C++中map,有三种类型:
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(log n) | O(log n) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。
搜索dfs,bfs
动态规划
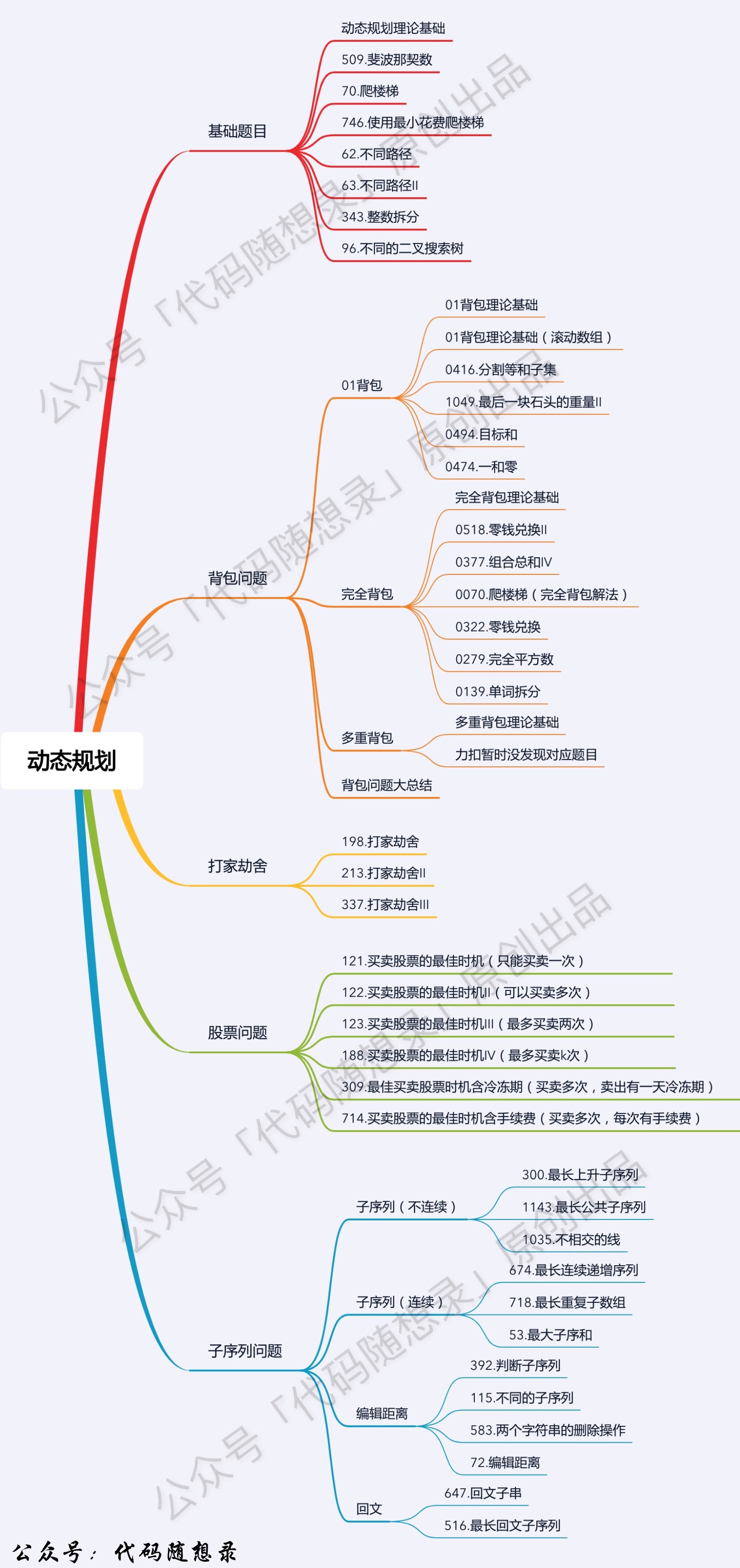
动态规划(记忆化搜索,剪枝)英文:Dynamic Programming,简称DP,如果某一问题有很多重叠子问题,使用动态规划是最有效的。
记忆化搜索,保存!(用哈希表!!!)
状态转移方程:就是个递推公式!(从一个状态到另一个状态就是状态转移)
就是要看这个状态是由什么状态得到的,就是说你的下标和函数分别含义是什么
!!!!
- 设计状态 定义一个状态数组dpi
设计状态dp[](是一个大类,每个可能都有一种状态,而我们要在意初始状态方便迭代,(也可以递归嘞)要在意n位置状态,将它的状态细化到n-1/n-2等直系状态,剩下的数学归纳法可证,所以让计算机自己跑)但因为涉及到了递归,就得注意递归要剪枝,不然会超时,因为他们得处于关联状态,这样题才能建立联系,所以dp[]
- 写出状态转移方程(只看离得最近的那几个,不要想太多,要找最直接的gua)
然后分析他是什么状态,这种状态可以是随机状态,那么通过转移方程i-1也得是这种状态,即可去可不去(不知道什么状态是因为他是随机状态,那也是一种状态啊,可以分类讨论细化呀)
- 设定初始状态
状态转移方程要先写,然后才知道需要几个初始量,
- 执行状态转移
然后写了初始量讨论后,再补上状态转移方程
就像数学题,我要先设变量x,然后才能通过x写出相应关系式来满足/表达出方程!!!!
- 返回最终解
最后return结果,切记要保证程序的健壮性!